Lecture et écriture de fichiers de données
Contenu
Lecture et écriture de fichiers de données en divers formats binaires ou caractères. Création et relecture d'en-tête décrivant la structure du fichier
Mots clés
lecture, écriture, fichiers, en-tête, header, format, binaire, ASCII, variables (définition)
Fichiers MUSTIG associés
Principes théoriques
On peut distinguer deux modes principaux de représentation des données pour l'enregistrement dans un fichier : le mode "formaté" et le mode "binaire"
Mode "formaté"
Le mode "formaté" utilise une représentation des nombres par des suites de caractères (chiffres, virgule ou point décimal, signes et symbole "exposant"), selon une représentation décimale. Son avantage principal est d'être directement lisible, imprimable et de pouvoir être vérifié par un quelconque éditeur de texte (logiciel de traitement de texte ou plus simplement éditeur de programme). La précision de la représentation peut être fixée par le nombre de chiffres utilisés pour chaque valeur numérique. Ce mode "formaté" a par contre l'inconvénient d'être relativement lent à lire et à écrire, puisqu'il faut réaliser une conversion entre du texte et une valeur numérique (cette valeur numérique est elle toujours représentée sous forme binaire dans la machine). Ce mode a également l'inconvénient d'être relativement encombrant, puisque chaque chiffre décimal est enregistré dans un octet (8 bits) alors qu'il suffirait en moyenne d'un peu moins de moins de 4 bits et qu'il s'y ajoute généralement des caractères peu informatifs (signes, point, saut de lignes, espaces)
On n'utilisera donc généralement ce format que pour des petits volumes de données.
Notons que l'avantage supplémentaire de ce format est sa transportabilité, puisque le codage "ASCII" des caractères est universellement employé, hormis pour la convention du caractère de séparation de ligne qui, suivant les machines, sera un "retour-chariot"(code 13), un "saut-ligne"(code 10) ou la suite des deux. Un transcodage pourra donc être nécessaire pour passer d'une machine à une autre, comme pour tout fichier texte simple.
Mode binaire
Dans ce mode, les données enregistrées sont directement les suites de "1" et de "0", exactes images de la représentation des nombres dans la machine de traitement.
Tout comme dans cette machine, il existe plusieurs modes de représentation binaire.
Les entiers non signés, pour mémoriser des nombres positifs.
Les entiers signés, pour mémoriser des nombres de signe non connu. On utilisera généralement le codage "complément à deux". On pourra également trouver le codage "binaire décalé", ou le nombre initialement négatif est rendu positif par ajout d'une constante.
Les nombres fractionnaires sont des nombres entiers dont on convient qu'il faut placer le point décimal à un emplacement donné (non écrit, donc fixe). Il suffit donc de diviser la valeur entière par une puissance de 2 convenable pour obtenir la valeur.
Les nombres flottants sont composés d'un entier et d'un exposant.
Tous ces formats binaires peuvent être de précision quelconque. On utilisera en général des nombres de bits multiples de 8, soit 8, 16, 32, ou 64.
L'avantage de ce mode binaire est son encombrement minimum et sa vitesse de lecture, écriture puisque qu'il n'y a en principe aucun transcodage.
Par contre, il peut y avoir des différences de représentation des nombres d'une machine à l'autre, et comme ce format est en fait une image de cette représentation interne, il y a un risque d'incompatibilité en cas de transfert d'une machine à une autre. Ce risque concerne principalement les nombres flottants. Mais de fait, presque toutes les machines récentes utilisent le format normalisé IEEE. Le seul problème restant provient de l'absence de standardisation de l'ordre des octets dans un mot (et cela concerne aussi bien les nombres entiers que les flottants) Certaines machines mettent d'abord les poids forts, les autres d'abord les poids faibles
Réalisation MUSTIG
Fichiers binaires simples
L'enregistrement d'un seul signal de "petite dimension" se fait très simplement par la macro disponible en bibliothèque. Il suffit de modifier le nom du fichier par celui désiré.
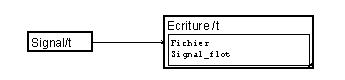
L'enregistrement se fait automatiquement avec le format du signal, c'est à dire par défaut en flottant 32 bits (R4). Pour enregistrer en entier, il suffit de convertir les données avant la macro d'enregistrement. Au préalable, il sera sans doute nécessaire d'appliquer un facteur multiplicatif pour faire tenir les valeurs dans la gamme autorisée par le nombre d'octets choisi.
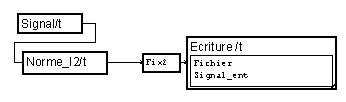
La lecture de fichiers se fait également par le macro de lecture disponible en bibliothèque. Il suffit de modifier le nom du fichier, ainsi que le nombre de valeurs à lire.
La macro de lecture est configurée par défaut pour lire des flottants 32 bits (R4). Pour lire un autre format, il faudra remplacer, à l'intérieur de la macro, le module de lecture
![]()
par celui désiré :
Pour faire cette modification, il faudra déverrouiller cette macro.
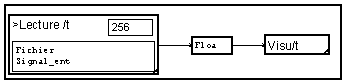
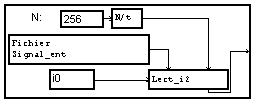
Il est possible d'automatiser le réglage de la longueur du signal lu afin de lire la totalité du fichier. Pour cela, on utilise le module
![]()
pour connaître la taille du fichier. Le nombre de valeurs est obtenu par division de cette longueur par le nombre d'octet par valeurs (4 pour 32 bits ). On obtient une nouvelle macro de lecture :
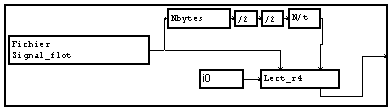
Inversion de l'ordre des octets
Pour exporter ou importer des données depuis une machine n'utilisant pas la même convention d'ordre des octets en mémoire, il faut placer le module "PERMoctets" juste après la lecture ou juste avent l'écriture.


Cas spécifique à MUSTIG/AU32
Le mode de représentation des octets sur le processeur TMS320C30 n'est pas standard. Les fonctions de lecture assurent un transcodage qui permet de lire les fichiers binaires flottants enregistrés sans carte AU32. Par contre, la fonction de permutation des octets est inutilisable dans ce cas. En cas de besoin, il est possible, avec MUSTIG/AU32, de lire un fichier comme des entiers 4 octets (ne pas alors chercher à les visualiser!), utiliser la fonction permute-octets sur ces entiers, et réenregister les données dans un autre fichier. Ce fichier pourra ensuite être lu comme du flottant.
Fichiers binaires à deux dimensions (suite de blocs)
Nous ne traiterons que l'exemple de la lecture d'un fichier. L'extension à l'écriture ne présente pas de difficultés supplémentaires.
Les modules élémentaires de lecture sont des modules "vectoriels", c'est-à-dire qu'ils lisent tout le signal en une seule opération. Tout ce signal doit donc être en mémoire, sa taille doit donc être relativement petite. Pour un signal long, il faudra le lire, et le traiter, en plusieurs blocs successifs. Pour cela, on peut le considérer comme un signal à deux dimensions, donc fonction de deux variables, qui en fait sont liées : l'indice "t" des valeurs dans un bloc, et l'indice "x" des blocs. La macro bibliothèque de lecture d'un signal à deux dimensions réalise directement cette opération. Supposons que nous désirions estimer la puissance, c'est-à-dire la moyenne du carré, de ce signal. Il suffit de calculer la moyenne de chaque bloc, par une moyenne selon "t", puis de moyenner ces moyennes partielles par une moyenne selon "x".
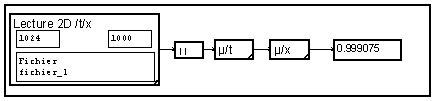
En fait l'ordre des moyennes est indifférent. Pour d'autres traitements sur des signaux divisés en blocs ou sur des signaux véritablement multidimensionnels, on se reportera aux exemples correspondants.
Il est intéressant de comprendre la structure de la macro de lecture.
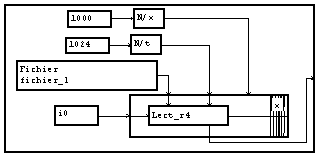
Elle comprend principalement un opérateur de lecture selon la variable "t", placé dans un paquet indicé par "x". Cette structure nous permet de savoir comment est organisé le fichier. Le module de lecture reçoit sur sa gauche l'adresse de début de lecture et fournit sur sa droite l'adresse suivant la fin de lecture. La première lecture est faite à l'adresse 0 du fichier. Le rebouclage du paquet fait que le bloc suivant débute immédiatement après la fin du premier bloc, et ainsi de suite. Les blocs sont donc lus de façon contiguë.
S'il n'en est pas ainsi, et que les blocs sont séparés par un nombre d'octets plus grand que la taille du bloc, on peut modifier la macro de lecture ainsi, en ajoutant la possibilité de paramètrer le début de la première lecture :
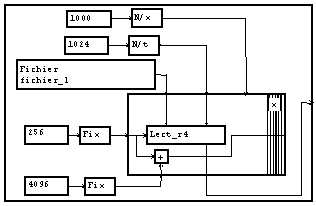
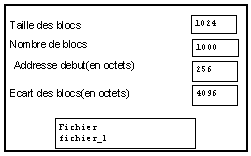
L'indication du nom du fichier est fait dans tous les exemples précédant à l'intérieur d'un module spécial "d'ouverture de fichier". L'utilisation de ce module présente l'avantage suivant : si le fichier désigné n'est pas trouvé, un dialogue de recherche est automatiquement appelé, et le nom du fichier choisi à l'aide de ce dialogue est mémorisé dans ce module. Par contre, ce module ne permet pas de réaliser une image où n'apparaîtrait que le nom du fichier (sans le nom du module), et surtout, il ne permet pas de construire dynamiquement le nom du fichier. Supposons par exemple que tous nos fichiers possèdent le même suffixe, il est commode de pouvoir ne modifier que la partie variable du nom. Pour cela, on utilise le module d'ouverture qui reçoit le nom en entrée sous forme d'une chaîne de caractères.
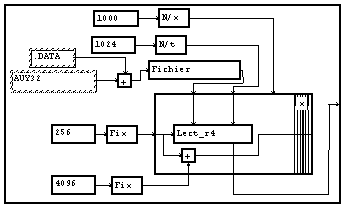
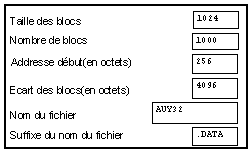
Fichiers binaires à deux dimensions (multiplex)
Une disposition courante pour enregistrer plusieurs signaux est de les multiplexer. Multiplexer 4 signaux X1, X2, X3, X4 consiste à en placer les échantillons de la façon suivante
X1(0), X2(0), X3(0), X4(0), X1(1), X2(1), X3(1), X4(1), X1(2), X2(2), X3(2), X4(2), ...
La façon la plus simple et la plus logique pour lire un tel ensemble de signaux est d'utiliser comme précédemment la macro de lecture 2D en permutant le rôle des variables. Si on appelle "t" la variable support des signaux, et "n" la variable indice des signaux, il suffit d'utiliser Lecture2D/n/t
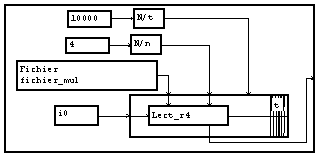
Si on a besoin d'effectuer un traitement par blocs, il faudra réaliser une deuxième boucle de lecture.
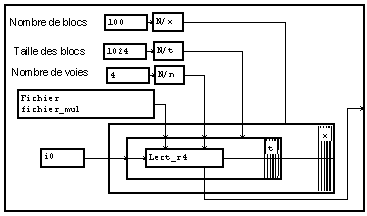
Mais on constate que chaque lecture élémentaire lit seulement un échantillon de chaque signal, c'est à dire une faible quantité de données. La vitesse de lecture est en conséquence souvent trop faible. Il est donc plus efficace de lire globalement tous les signaux d'un bloc et de les démultiplexer ensuite.
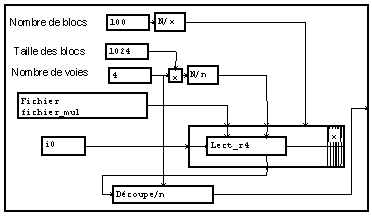
Lecture simultanée de plusieurs fichiers
Une autre façon d'enregistrer plusieurs signaux est d'utiliser un fichier par signal. On peut traiter cet ensemble comme un seul signal à deux dimensions et bénéficier pour cela des facilités offertes par MUSTIG.
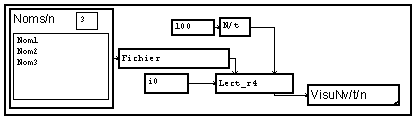
La macro "Noms" permet de créer une fonction de la variable "n" de type chaîne de caractère (voir les exemples de manipulation de chaîne de caractères). La suite du graphe concernant la lecture de fichier est la même que s'il n'y avait qu'un seul signal à lire : le mécanisme général de blouclage implicite de MUSTIG s'applique ici à ces opérateurs. Nous n'avons mis qu'un seul module de lecture, mais les structures précédentes de lectures par blocs pourraient être utilisées.
Utilisation d'un bloc "en-tête"
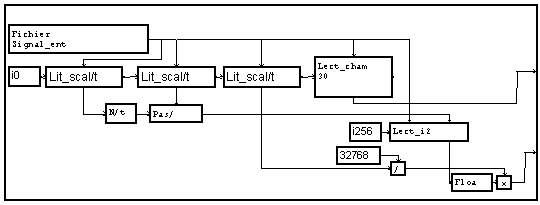
Dans tous les exemples précédents, nous avons enregistré uniquement les données. Il peut être utile d'ajouter à ces données quelques paramètres de cet enregistrement, et de les placer dans un premier bloc du fichier que l'on appellera "en-tête". Nous choisissons ici de mettre dans une en-tête 64 valeurs numériques flottantes (32 bits). Nous n'utiliserons en fait que les 3 premières pour mémoriser :
- le nombre d'échantillons du signal, obtenu par ![]()
- le pas d'échantillonnage, obtenu par ![]()
-la valeur réelle correspondant au codage sur l'entier de valeur maximum fournie par la fonction de conversion entier.
La macro "Liste" forme un signal de ces différentes valeurs, qui est écrit en binaire par le module d'écriture placé devant le module d'écriture des données.
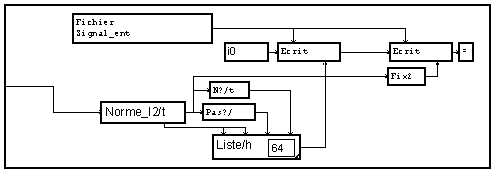
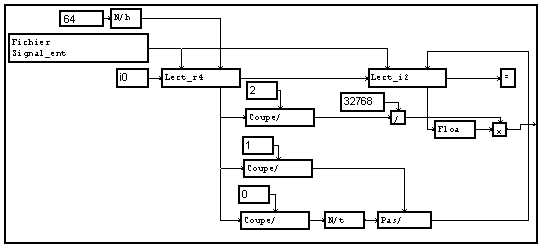
De façon similaire, la lecture de cet en-tête se fait par un module de lecture placé devant le module de lecture des données. L'accès aux valeurs élémentaires est fait ensuite par des modules "coupe". Ces valeurs permettent ensuite de redéfinir la variable "t" support du signal avec les caractéristiques de celle du signal enregistré, et de renormaliser ce signal aux valeurs originelles.
Au lieu de réunir tous les paramètres en un signal, on peut préférer écrire ces paramètres un par un. C'est généralement plus lent, mais cela est sans importance pour l'en-tête. Cela permet surtout de mélanger les types de données et en particulier de mettre des chaînes de caractères. La seule difficulté est que le module d'écriture n'existe que sous forme vectorielle. La solution est de créer un signal de longueur "1", fonction d'une variable temporaire. Cela est réalisé par la macro "ecrit_scal" :
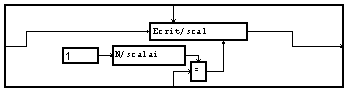
Ces macros sont placé en chaîne suivant l'ordre d'enregistrement désiré.
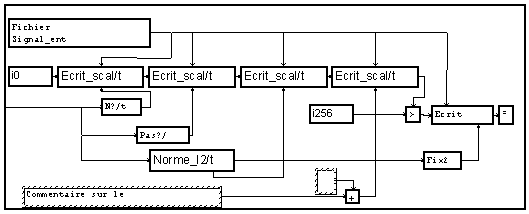
L'adresse d'écriture des données est ici repositionné à 256 ( = 4 x 64) pour garder une taille d'en-tête constante. Noter que le module > sert uniquement à créer une dépendance entre le module d'écriture des données et la chaîne des modules d'écriture de l'en-tête afin d'assurer l'ordre temporel des opérations (c'est la dernière écriture dans le fichier qui définit la taille de celui-ci à la fermeture).
La lecture peut également se faire de cette manière, grâce à la macro "lit_scalaire".
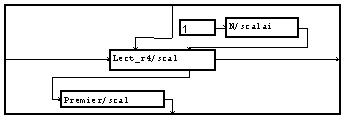
La lecture de la chaîne de caractère est, elle, faite par "lect-champ". (On n'a pas ici créé de dépendance entre la lecture de l'en-tête et la lecture des données, car il n'y a pas à s'inquiéter de l'ordre des opérations en lecture).
Fichier formaté
Cet exemple montre comment relire un fichier de données de type "texte", provenant d'un spectrographe à rayons "X". Ce fichier, lu avec un éditeur de texte, se présente ainsi:
GDAL2
TUBE CUIVRE FILTRE NICKEL
50 KV 44 MA
GdAl2 01-04-1991 17.04 PROGRAM 10
441
18
.1
9868
10041
9977
10082
10031
10080
10235
.....
.....
Il est composé de 4 lignes de commentaire, puis 3 lignes indiquant successivement le nombre de valeurs du fichier, l'angle de départ du balayage puis l'écart angulaire entre deux mesures. Ces trois valeurs correspondent dans MUSTIG à la longueur du signal, à l'origine de la variable, et à son pas d'échantillonnage. Ensuite viennent les valeurs successives du signal, à raison d'une valeur par ligne.
Toutes ces lignes sont lues par le module "Lect_champ". On paramètre ce module avec la longueur maximum d'une ligne (100 pour les commentaires, 30 pour les valeurs numériques : il n'y a pas d'inconvénient ici à majorer cette valeur) suivie du caractère "fin de ligne"(non visible). La macro "commentaire" lit les quatre premières lignes, qui sont ensuite rassemblées en une seule chaîne de caractères pour pouvoir être transmise par une seule connexion à la macro de visualisation.
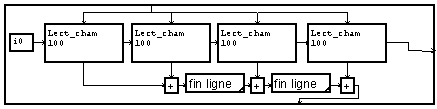
Les trois lignes de paramètres sont lues par les macros "lect val".
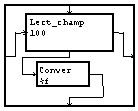
La ligne est lue comme une chaîne de caractères par "Lect_champ" puis le module "Convert" transforme cette chaîne en une valeur numérique.
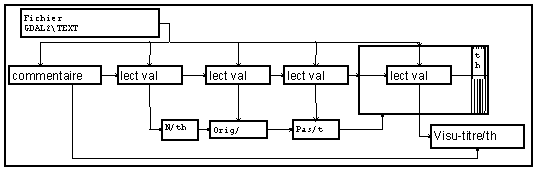
Ces paramètres sont utilisés pour définir les caractéristiques de la variable "th" support du signal. Les valeurs numériques sont ensuite lues par la même macro placée dans un paquet indicé par cette variable "th". La macro de visualisation est construite à partir d'une visu standard, complétée par un rectangle dans lequel est imprimé le commentaire. (Voir exemples de modification de visualisations).